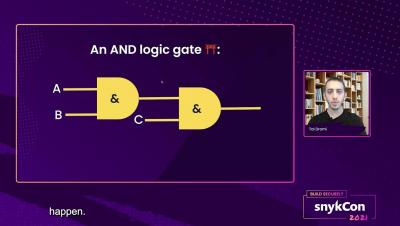
How to Use the Snyk CLI to Fix Vulnerabilities in Your Application: The Big Fix
Brian Vermeer, Developer Advocate at Snyk, demonstrates how you can use the Snyk CLI to fix vulnerabilities in your application. Join us for The Big Fix, an event that brings developers and security practitioners round the world to find and fix vulnerabilities. Let's make the Internet a safer and better place than before!